How to Convert Docx to HTML
For my current side project I needed to allow a user to upload a docx file and then continue editing it from their WordPress dashboard.
I chose docx because it is an open standard based on XML. I figured that might make things somewhat easier.
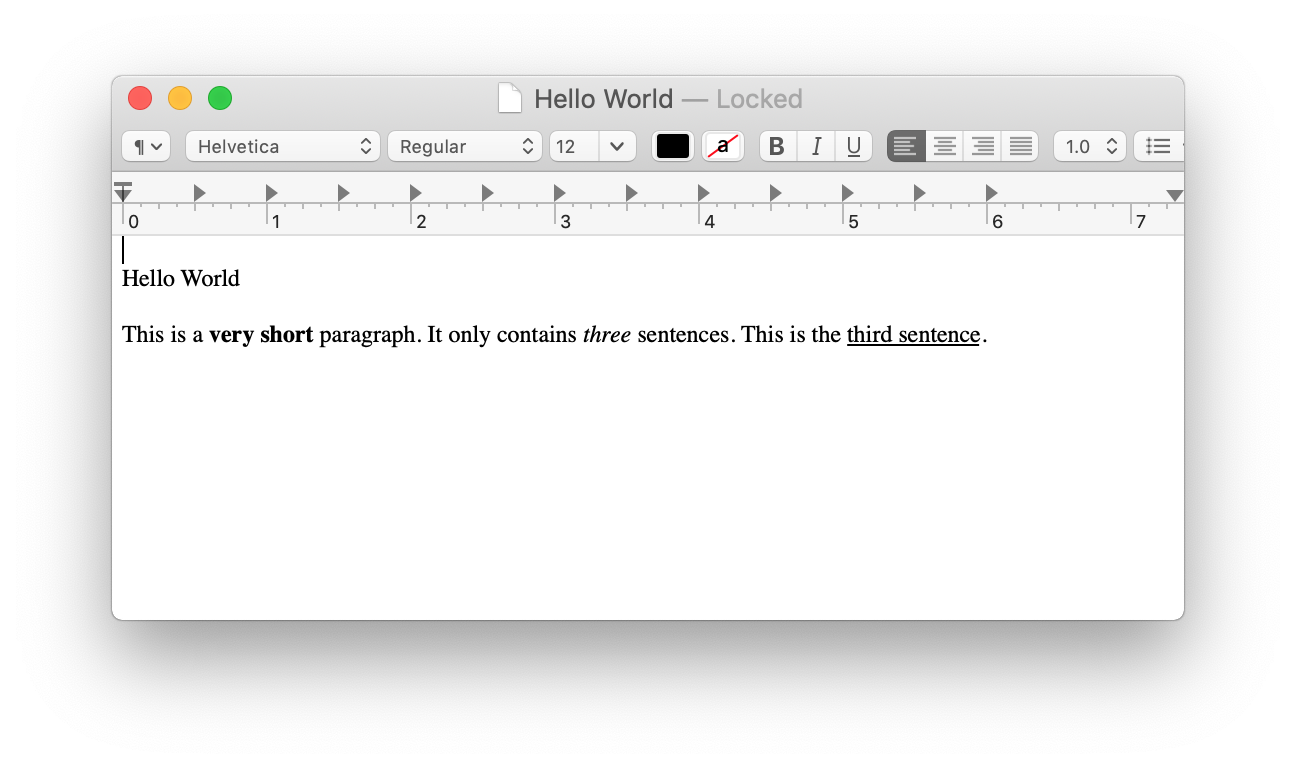
Unzip Docx file
Many modern formats these days are compressed directories containing XML files. Because XML files tend to get bloated, as we will see, text compression is important but also very effective.
Docx looks like this when unzipped.
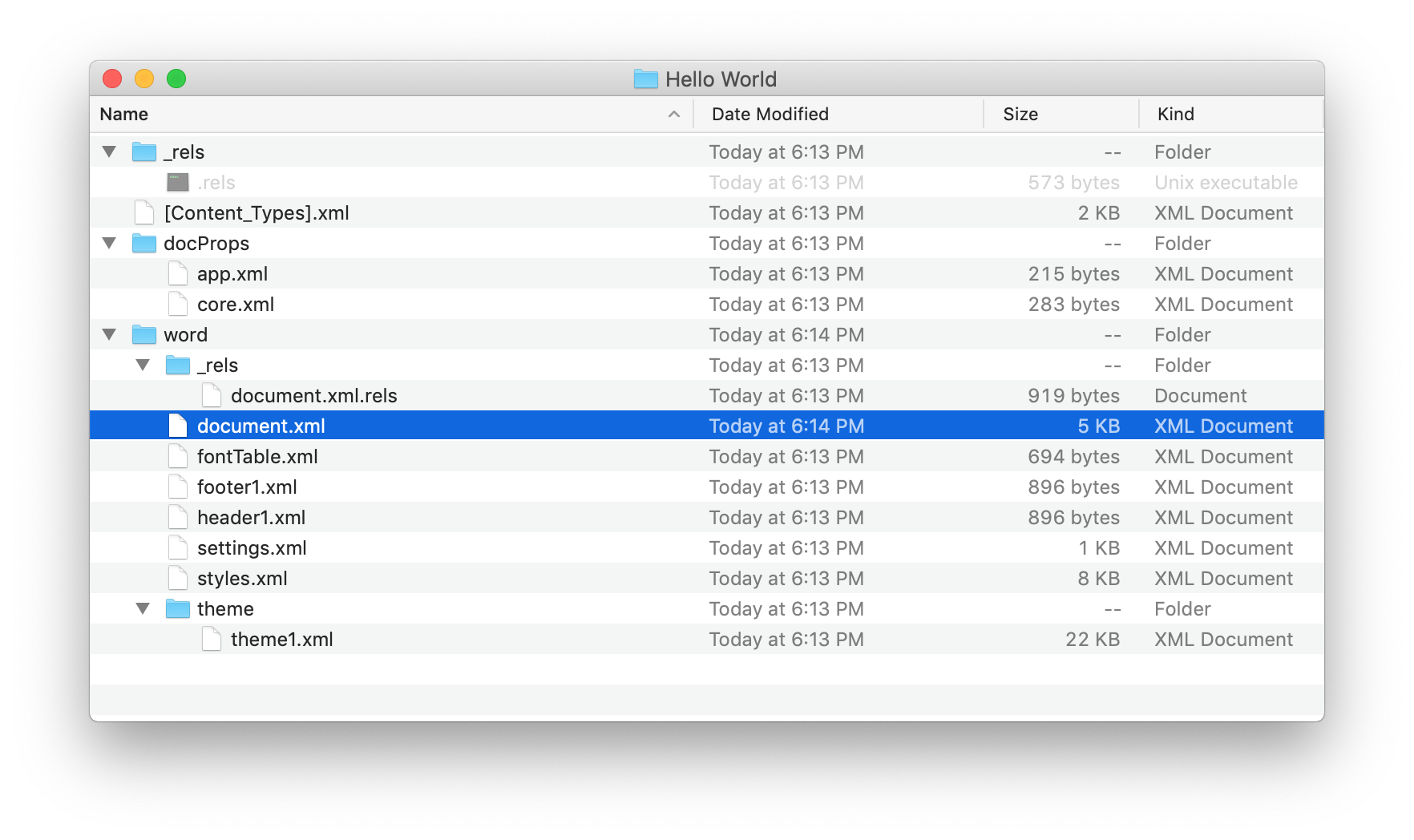
For our purposes the important file is /word/document.xml. That’s were the textual content of the document is stored.
When unpacking this is what you can expect. I’ve formatted it just a bit…
<w:document xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" mc:Ignorable="w14"> <w:background w:color="FFFFFF"/> <w:body> <w:p> <w:pPr> <w:pStyle w:val="Body A"/> </w:pPr> </w:p> <w:p> <w:pPr> <w:pStyle w:val="Title"/> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> </w:rPr> </w:pPr> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="it-IT"/> </w:rPr> <w:t>Hello World</w:t> </w:r> </w:p> <w:p> <w:pPr> <w:pStyle w:val="Default"/> <w:spacing w:line="280" w:lineRule="atLeast"/> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> </w:rPr> </w:pPr> </w:p> <w:p> <w:pPr> <w:pStyle w:val="Default"/> <w:spacing w:line="280" w:lineRule="atLeast"/> </w:pPr> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t xml:space="preserve">This is a </w:t> </w:r> <w:r> <w:rPr> <w:b w:val="1"/> <w:bCs w:val="1"/> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t>very short</w:t> </w:r> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t xml:space="preserve"> paragraph. It only contains </w:t> </w:r> <w:r> <w:rPr> <w:i w:val="1"/> <w:iCs w:val="1"/> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t>three</w:t> </w:r> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t xml:space="preserve"> sentences. This is the </w:t> </w:r> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:u w:val="single"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t>third sentence</w:t> </w:r> <w:r> <w:rPr> <w:sz w:val="24"/> <w:szCs w:val="24"/> <w:rtl w:val="0"/> <w:lang w:val="en-US"/> </w:rPr> <w:t>.</w:t> </w:r> </w:p> <w:sectPr> <w:headerReference w:type="default" r:id="rId4"/> <w:footerReference w:type="default" r:id="rId5"/> <w:pgSz w:w="12240" w:h="15840" w:orient="portrait"/> <w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="864"/> <w:bidi w:val="0"/> </w:sectPr> </w:body> </w:document>
As you can see it is well formed XML; I wouldn’t expect anything less from Microsoft. With a little trial and error, i.e., adding bold and italics randomly and seeing what changed in the XML I was able to figure out how it’s formatted.
- Paragraphs are enclosed in w:p tags.
- Groups of words with formatting are wrapped with w:r.
- The text itself is wrapped with w:t.
- Headings are set with a w:pStyle w:val=“Heading?”
- The ? should be replaced with a numeral representing the heading level [1-6].
- A word group containing a self-closing w:b tag is bold.
- A word group containing a self-closing w:i tag is italic.
- A word group containing a self-closing w:u tag is underlined.
- The type of underline is defined with w:val. =“single” will be a single underline.
There’s a whole lot more here including Typeface, font size, etc. For my purposes I wanted to keep basic formatting, but only basic formatting. So this code will not take typeface or font size into account. But it should be a good start for you if you’d like to do that.
I didn’t start out trying to re-invent the wheel but couldn’t find a good solution.
DOCX to HTML Free already is out there. But it couldn’t handle files of any significant size. There were existing php classes that could, but these solutions were costly… So I decided to donate some of my time to the community.
Solution #1
The initial idea was to loop through all w:r tags and enclose them in the formatting tags that they contain. That did work; it created semantic HTML that included all formatting in the document. The problem was that when docx files get bigger the XML gets messier. Not that it’s not well-formed. But I noticed that there were entire sentences broken up to single words and wrapping each word in a bold tag. I found several instances with single spaces wrapped in multiple formatting tags. Basically, everything I hated in WYSIWYG HTML generators.
The quick and dirty solution #2.
For solution #2 I keep track where text first gets assigned a formatting tag, mark that it’s open, and only close it when there isn’t a that formatting tag anymore.
This solution almost works. It successfully creates non-semantic HTML in the rare cases where formatting tags overlap each other.
In a sentence like this one where part of the sentence is bold overlapping part of it that is italic.
You end up with code like this:
In a sentence like this one where part of the sentence is bold overlapping part of it that is italic.
BIG NO NO
I call this the quick and dirty solution because I didn’t go the extra mile. People usually don’t format their text like the example above. It’s mostly academic. So I kept that solution. But in order to make sure my code is semantic I ran it through simplexml_import_dom()->asXML to fix cases of non-sematic html. The only issue is that it truncates the formatting when semantics break down. Since this will be a rare case I’ll ignore it for now.
At some point I’ll revisit this solution and work out the logic so that the code is well-formed, not bulked up, semantic AND can take rare formatting cases into account.
And now… For the Code:
open($xmlFile); // set up variables for formatting $text = ''; $formatting\['bold'\] = 'closed'; $formatting\['italic'\] = 'closed'; $formatting\['underline'\] = 'closed'; $formatting\['header'\] = 0; // loop through docx xml dom while ($reader->read()){ // look for new paragraphs if ($reader->nodeType == XMLREADER::ELEMENT && $reader->name === 'w:p'){ // set up new instance of XMLReader for parsing paragraph independantly $paragraph = new XMLReader; $p = $reader->readOuterXML(); $paragraph->xml($p); // search for heading preg\_match('/';
// loop through paragraph dom
while ($paragraph->read()){
// look for elements
if ($paragraph->nodeType == XMLREADER::ELEMENT && $paragraph->name === 'w:r'){
$node = trim($paragraph->readInnerXML());
// add
tags
if (strstr($node,'